|
I am not an economist. Basic economics makes some sense to me. Supply and demand is pretty basic and makes sense. Inflation makes sense. Too much money chasing too few goods and prices go up. What does not make any sense to me is how our national bank fights inflation. The logic of the inflation fighters is if you increase the interest rate the cost of stuff will increase thereby discouraging purchases. But wait a minute, is not increasing prices part of the definition of inflation? Fine they say, raising the interest rate only reduces the demand for loans, which discourages expensive purchases by consumers and curbs expansion by businesses.
So, if I as a consumer have a lot of cash but am discouraged about buying expensive items maybe I’ll take that money and buy a bunch of smaller items. In other words, sending too much money after the same amount of goods in the marketplace. Demand is up, prices are up, inflation is up. Exacerbating this, businesses are discouraged from borrowing so they cannot expand capacity to meet the increased demand for consumer goods. So, it seems to me that raising interest rates fuels inflation. It is like throwing gasoline on a fire. I would love a response from a competent economist or anyone else for that matter.
0 Comments
Most mornings I listen to the Daily from the New York Times as I drink my coffee and work on my puzzles. Today, Michael Barbaro, was hosting and his guest was nationally renowned pollster, Nate Silver. I think that Michael had all the right questions but I think that Nate did not have all the right answers.
First, let’s recall that polling these days is a fraught enterprise. It is so because achieving an unbiased sample is nearly impossible to achieve. I have documented in this journal my concerns about the accuracy in polling (Presidential Polls and What to Pay Attention to, 8/19/2019). I stopped doing most public opinion polling years ago because of the sampling problem. Samples simply are not random because respondents are free to choose to respond or not. So, let’s remember this as we go forward thinking about polling results. All elections are local. So, any shift in a national poll may not have any implications in changes for local results. In other words, if we are looking for how a specific race is going to turn out we need local numbers. The national trend is meaningless. If, for example, the shift in the national trend all came in states that were already leaning a particular way the shift would have no impact. You really need more information than the results of a national poll. The part of the conversation between Michael and Nate that I found most interesting was when they were talking about the shift in the national poll from favoring Democrats in the summer to the fall poll showing a preference for Republicans. Really? The shift according to Nate was a 3% margin for Dems in the summer to a 1% margin for Republicans. Nate thought that was significant. I say poppycock! Importantly the magnitude of the shift, what Nate called 4% is misleading. The shift is really only 2%. Imagine that the Dems were leading 51% to 48% and that shifted to 50% favoring the Republicans and 49% favoring the Dems. That result is achieved by a shift of 2% of the sample moving from Democrats to Republicans. All of this is well within the margin of error, which is to say there is no real difference here. Even if the numbers were accurate the difference would be effectively nil. I think you need to take the results of current polls with a grain of salt. I also believe that you can’t apply national polling results to local elections. Think about it. Nationally Democrats have an overwhelmingly large portion of the population. But we know that because of our goofy electoral system and gerrymandering that there is a close balance of power between the national parties. National polls should show Democratic dominance but don’t. Why?  Robert J. Siegel and Edward Siegel
7/27/22 The first pictures from the Webb space telescope are awe inspiring. The photos from Hubble space telescope were astonishing but we now see that the photos from Webb are far more detailed, clearer and spectacular. One of the goals of the Webb is to look back in time to just after the so called Big Bang. We maintain that what Webb will find is that time extends back to well before the Big Bang. In fact, the first photos already provide us evidence. Before you dismiss us as cranks please read on. The photo above is the first one released by the Webb scientists. To capture this image the telescope was aimed at what had previously been “an empty region of space”. The mission scientists tell us that the oldest of the galaxies we are seeing are sending us their light from some 13 billion years ago. I have no doubt they are correct. How did we get here before their light did? Are we traveling faster than the speed of light? Moreover, what if they now choose another region of space to aim the Webb, one that is 180 degrees opposite from the one they first chose. Would they also get images of galaxies 13 billion light years away? We believe they would. That would mean that the two opposite regions of space are 26 billion light years apart! How did they get that far apart when the universe itself, according to the Big Bang, is only 13.6 billion years old? Another question arises if we are able to see 13 plus billion years in any direction back to just after the Big Bang does that put us in the middle of the universe. In other words, do we now have a Sol-Centric universe? Doesn’t seem Ptolemeic? And if we can see 13 billion years in any direction does that mean that at there is a 13 billion year old perimeter to the universe or is that just because that’s the limit of our instrumentation? Some believers in the Big Bang will tell us that these distances were spanned during that magical period they call Inflation when all of the laws of physics were suspended for an infinitesimally short period of time. In other words, all the matter in the universe traveled at beyond the speed of light, a speed which Einstein has told us is inviolate, and then came to a screeching halt only to start speeding up again in our currently expanding universe. Let’s not forget that all this primordial stuff magically popped out of a singularity no larger than the period at the end of this sentence. Really? If you take a look at the Big Bang, it bears a distinct similarity to the biblical account of creation. It’s no wonder. The original promulgator of the theory was one Georges Lemaitre, a prominent and extremely accomplished astrophysicist. He was also a Belgian Catholic priest. That someone with his acumen and religious beliefs could come up with a theory that was consistent with both the bible and much of the known physical evidence would have made Galileo envious. Of course, the Big Bang is not consistent with all of the physical evidence. That’s why they had to come up with the magic of inflation. Violating the cosmic speed limit is the big one. I am also tempted to make snarky comments about the singularity but we’ll just ask a few questions. Why only one singularity? Why did it explode? How was it created in the first place? The Big Bang Theory is a wonderful invention of a powerful mind, supplemented by the efforts of many other great minds, but we think it is time for our learned friends to give up the orthodoxy, admit the emperor has no clothes and look for a more parsimonious explanation for our universe.  By Robert J. Siegel MD and Edward Siegel MA
Note: This is an update of a previous entry The television news show 60 Minutes recently aired a story about the imminent launch of the Webb Space telescope. In that story they talked about how it will be used to look back in time to a period shortly after the Big Bang. One of our enduring interests lies somewhat outside the boundaries of our professional training. We are physics enthusiasts. One of the issues that keeps coming to our attention is this claim of seeing light that is just now arriving here from soon after the Big Bang. The 60 Minutes story is just the latest of these claims. The question we have is simple, how could we have gotten here before the light from just after the Big Bang? Some derivative questions are: Wouldn’t we have had to travel faster than that light to have gotten here before the light from just after the Big Bang? What implications does that have for the Big Bang? Inflation? Please, it reminds us of the old cartoon depicting a huge blackboard covered with intricate equations ending with, “Then a miracle occurs.” If someone has a coherent explanation, we would love to hear it. The scientists interviewed for the 60 Minutes piece also claimed that the new telescope would shed light (no pun intended) on issues of Dark Matter and Dark Energy. We would just like to remind our readers that other than the inadequacy of current gravity theory, there is no other evidence for Dark Matter. It remains nothing more than a hypothetical construct created whole cloth for the purpose of accounting for this shortcoming. We submit that a more mature theory of gravity will resolve the mystery of why galaxies hold together. Newton and Einstein provided great advances and insight into gravity. Now we need another advance. Dark energy is another hypothetical construct that lacks a sufficient theoretical base. Finally, the 60 Minutes piece opens up by claiming that the Webb telescope will be collecting only infrared wavelengths from shortly after the Big Bang because that was all there was about 100 million years into our new universe. We submit that if they look for wavelengths in the visible part of the spectrum, they will find those wavelengths too. I am a huge baseball fan. I go to many games every year and the games I don’t go to I watch on TV. There are very few games that I miss. Living in the Tampa Bay area means that not only do I have a great baseball team to follow but the team provides us fans with two great television announcers. Dewayne Staatz and Brian Anderson. Both are knowledgeable and fun to listen to, although they could use someone with more of a hitter’s perspective. The whole broadcast team is outstanding, including the radio broadcasters who are also first rate. I’m not going to dwell on Mr. Staatz, although his name makes his relevancy apparent. Mr. Anderson is my main focus.
One of the things that first let me know that Brian was not your average Joe jock turned color commentator was that he was always talking about sample size. Who does that? Statisticians and maybe a handful of other nerds. One of the main foci of my current practice is helping DNP (Doctor of Nursing Practice) students determine the sample size for their doctoral research paper. Scientists of all sorts are concerned with sample size but baseball announcers! Brian even has Mr. Staatz talking about sample size – too cool. But what really got me excited the other day was when Brian started talking about how much he liked numbers. He said his interest in numbers came from following baseball and from an early age paying attention to things like batting average and earned run average. That was exactly how I started my appreciation of numbers. I would pour over the box scores and if the paper didn’t have the up to the minute batting averages of my favorite players, I would do the calculations myself. Of course, in those days there were no up to the minute stats during the games or even electronic calculators let alone computers to help you with the keeping abreast of the changes. All of the calculations were done either by hand or heaven forbid in my head. Although the book, Moneyball, didn’t come out until 2003 I knew there were many more measurements that could be used to help with baseball decisions. In the mid-seventies a friend and I sent a letter to the Milwaukee Brewers offering to be their team statisticians. We had both been teaching assistants for the advanced statistics course. The Brewers never got back to us. That was not the first great idea I had that went nowhere nor would it be the last. The friend was Steve Maisto who today is the leading authority on substance abuse treatment efficacy. Imagine what he could have done for the Brewers if we had been given the chance to apply that intellectual power for them. Today, every sport has a set of statistics that they use to help understand the game, enhance performance, select players, and so on. Looking at the statistics adds a whole additional level of enjoyment and understanding of the game. It excites you to know that a quarterback, like a Tom Brady, is coming to your team because he’s got the “numbers” that let you know this guy can perform. The same is true in all walks of life. Numbers tell the story. In business, medicine, research, politics, engineering, sports, even in entertainment. But for me and Brian Anderson and probably millions of others we learned our appreciation for numbers from a love of baseball. “They will come.” -from Field of Dreams Let me know what you think. Leave a comment. I promise you won’t go on my email list. I don’t have one. One of my childhood friends complained to me about how the COVID 19 virus has disrupted his social life. He asked me what I thought about the current situation. The following is what I sent him. I hope you find this helpful.
I think we are UNDER-REACTING! Take a look at Italy. Nearly 2000 deaths already. Their health care system is totally overwhelmed. Here are some simple numbers that should help give you perspective. The Germans are predicting a 70% penetration rate. That means 70% of their population will at some time be infected. I think that number is low since no one has immunity to this disease. If we assume the same penetration rate for the USA with our population of 320 million people that means 224 million people will be infected. Not every infected person will be critically ill. For most it will be like a cold. However, it's not a cold or the flu and a lot of folks get very ill and require hospitalization. Current estimates are about 15% to 20% of those infected will require hospitalization. That means conservatively around 33 million people will require hospitalization! The current efforts are focused on slowing the spread of the infection to avoid overwhelming our hospitals, because once that happens the deaths that result will include others that require hospitalization for non-COVID - 19 problems. Current estimates of the mortality rates range from 2% to 4% but those numbers are unreliable. Even if its as low as the rate from the common flu of .1% that yields over 200,000 deaths. About triple the number from the flu. If its the lower number of current estimates, 2%, we are talking about 4,000,000 deaths. Check for yourself how many deaths have occurred in our various wars. So yeah, i think we need to take this very seriously. We are all in this fight to slow the spread of this disease. Stay well. You have heard it many times before, “Numbers don’t lie, people do.” The other day while I was enjoying my brother’s hot tub he said, “If I told you that one product had a rating in the seventies and another had a rating in the sixties, wouldn’t you get the impression that one had a higher rating than the other?” “Well sure”, I said. He responded, “Well, the ratings were actually, 70.1 and 69.9.” He got me! It took me back many years to a time when a colleague asserted that his favorite method of data conversion was superior because it yielded a correlation of .71 when predicted scores were compared to actual scores, versus an alternate method which yielded a correlation of .70. He knew better than to make that assertion and I took him to task for it. The point is that these kinds of situations abound. Small differences may or may not be real. Remember the margin of error. And remember to look at the details.
Our discussion moved on to talking about misleading with averages. If you averaged the temperatures of his swimming pool and his hot tub the average would give you a very comfortable 81 degrees. But the pool was 60 degrees and the hot tub was a near scalding 102 degrees. The weighted average might have been more accurate and oh, by the way what about using the centigrade scale which starts at absolute zero (not necessary in this case, work it out). What about average height of the family? Does that tell you anything meaningful? Probably not. You may want the range or even the height of individual family members. One of the most well known deceptions with numbers is when a salesperson tells you, “It costs only …”. What they are telling you may be the price of item or service but it is most certainly not the cost to you. There’s sales tax, dealers fee, transportation fee, license fee and many other well known price add-ons. And of course, let’s not forget training costs, insurance costs, and all the other big ticket costs that come with some products. Oh, you actually want to use that telescope? Well, you need software. What’s that you have a Mac, well the software will run only on a PC. And on and on it goes. No one really lied to you but none the less you were certainly deceived. It can be much more subtle than that. In science accuracy is everything. While to those of us mortals who only deal with simple measurements the recent change in the length of the official foot doesn’t mean a whole lot. But if you are a surveyor or a maker of maps the change can be profound. The length of a foot, strangely enough, is defined in terms of meters. The standard American survey foot up until recently was 0.304800609601 m. But now they have gone to the international standard foot which is 0.3048 m. By looping off those extra digits they have made a bit shorter and the width of the USA is a whopping 30 miles, or so, wider! Okay, so when we measure the kids’ height it doesn’t make a difference so who cares? But, if your sending a missile from say North Korea to the US it could make a big difference. Maybe that’s why the changed it, to confuse the North Koreans. Knowing what a number means and knowing how to obtain the correct number is what statistics is really all about. One of these days we may talk about the simple yet fundamental concept of measurement theory T + e = X. True value plus error equals measured value. Until then think about it. There is an article in the latest edition of Scientific American about the short comings of using standard statistical significance testing as the criterion for publishable results. Without going into all the nuances of significance testing it basically boils down to this. When you do a scientific study or research project you compare a group that receives an experimental treatment to a control group that does not get the treatment. Using an appropriate statistic for the comparison like a t-test or an F-test or a chi square you test to see if the difference is large enough to claim that it is probably due to the experimental treatment. Using an F or t statistic you compare the difference between the experimental and control group relative to the amount of error. Using chi square the difference is compared to expected values. The criterion is usually set so that if the likelihood of statistic is less than .05 (p < .05) it is said to be statistically significant. The p value is supposed to be set prior to the start of the experiment (a priori) and is sometimes set to a more stringent p < .01. You use a statistical procedure because results are rarely clear cut and you generally can’t test everyone in a population. You use a sample to see how things work out So, as an example, and just for fun, let’s say that you want to test your Brand New chocolate milk and on how it effects learning in kindergartners. You take a large (really large) class of say 60 children and split it into three groups. One group gets your brand new chocolate milk. Another group gets some other brand of chocolate milk, the third group gets plain white milk and the fourth group gets no mild at all. Now there are many more groups and procedures that you could want to employ as proper controls but we’re keeping it simple. The learning test how many types of animals each child could correctly identify. Let’s say our results look like the following. 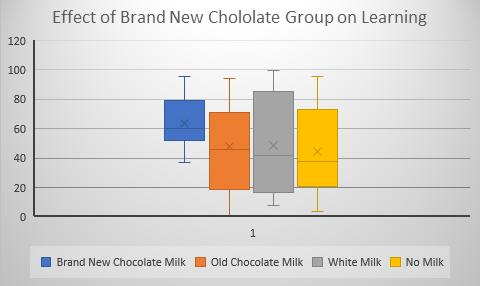 Notice that the X’s in the middle of each box indicate the average mean score for that group. The means for the four groups are given below:
Brand New Chocolate Milk 64; Old Chocolate Milk 48; White Milk 49; No Milk 44; Clearly there is something very different about the mean for the Brand New Chocolate Milk. All the other means are in the mid to high 40s and our group of interest is 64! Yet, a statistical test done on the data that created the pretty graph and table of means yielded a probability greater than .05. What are we to think?! Okay, I cooked this data just to get this result but the point is made. This result would never make it into the literature because it was not Statistically Significant! “Give me a break”, you say. I agree, this result should be filed under the category, Suggestive but not Conclusive, and should have a home somewhere in the literature so that it may be followed up on. What about results that go the other way. Data that is narrowly significant and doesn’t seem to have much practical significance because the effect may be small. This too should have place in the literature. The great thing about science is that findings don’t become facts until they are replicated. At least that’s the way it’s supposed to work. Unfortunately, it doesn’t always work. Worse yet sometimes “facts” are admitted to the scientific catalog that simply are not so and sometimes these “facts” don’t die an easy death. Take, for example, the mythology about the evils of dietary salt. Somehow salt became the evil deadly ingredient in our diet, largely on the basis of one faulty study. A review in the Journal Science over 20 years ago clearly demonstrated that salt is not the great evil it had been claimed to be. Yet here we are today still seeing all kinds of ads and literature claiming food low in salt to be more healthful. This may be the topic of a future missive but for it should serve to show that there is an impact of false positives and that once something is incorporated into the truth catalog it’s hard to get rid of. So, what are we to think of statistical testing? It seems as though we have moved far afield. We haven’t moved far afield. Statistical testing was never meant to be the be all and end all of scientific truth it was meant to be used as a tool in guiding thinking about outcome of an experiment or research project. It has evolved to be to become an arbiter of absolute truth and that is the problem. Facts are not easy to come by scientific in research. Our literature is biased by only admitting findings that exceed the .05 criterion. This allows false positives (things that appear to be true but are not) to creep in but not false negatives (things that appear to be false but are not). Some advocate the use of confidence intervals to get around the shortcomings of significance testing but it is only a slight of hand, since confidence intervals are essentially the same thing as a p value and their use adds nothing to our understanding. The only thing that helps to clarify our understanding is more and better research seasoned with a thoughtful use of statistics. If you enjoy reading this journal and would like to be notified as new entries are added go to the contact page and send me your email and I will add you to the list of readers and I promise I will not sell or give away your email address to anyone. I keep seeing talking heads refer to national polls showing the current president trailing various Democratic candidates indicating that these candidates may win in a general election in the fall of 2020. Let me disabuse you of this notion. As you may recall the candidate that won the presidential election in both 2000 and 2016 LOST the in the raw vote count. That is because the United States of America has a crazy electoral system for the presidential election. It’s called the electoral college. The idea of the electoral college was to give a little more weight to small states. The number of electors each state received was to be based on the total number of members of congress from each state. The District of Columbia also gets 3 electors based on the 23rd amendment, which specifies that the District receive at least as many electors as the smallest state. So, what matters in the presidential election is the number of electors a candidate accrues. Most states (all but Maine) work on a winner take all basis. In other words, they give all their electoral votes to the candidate that win the popular vote within that state. It doesn’t matter if a candidate wins by a 1 vote margin (let’s not get into recounts) or a 1 million vote margin, either way all of the electoral votes go to the winner. So, if we want to have some clue about who is likely to be elected as our next president, we have to look at the polls on a state level not a national level. But, as was noted on these pages in an earlier journal (March, 2019), I remarked on the failing of polling in a Minnesota election and offered that the failure was due to poor sampling. While polling has improved in recent years, different organizations are polling in different states and may be putting forth a better or lesser quality effort. To get a good sense of who may win the Presidency we need to look at which candidates are carrying which states and count up the available electoral votes. As I was writing this piece a segment appeared on the Rachel Maddow show that spoke directly to what I’m writing about. You can see it here. https://www.msnbc.com/rachel-maddow/watch/disapproval-of-trump-higher-than-approval-in-ten-states-trump-won-66043461738 The map below was developed from the survey results of a group called Civiqs, you can find them here, https://civiqs.com and presented on the Rachel Maddow show. The numbers inside the states show how many points Trump's approval rating is below his disapproval rating in states where he won in 2016. 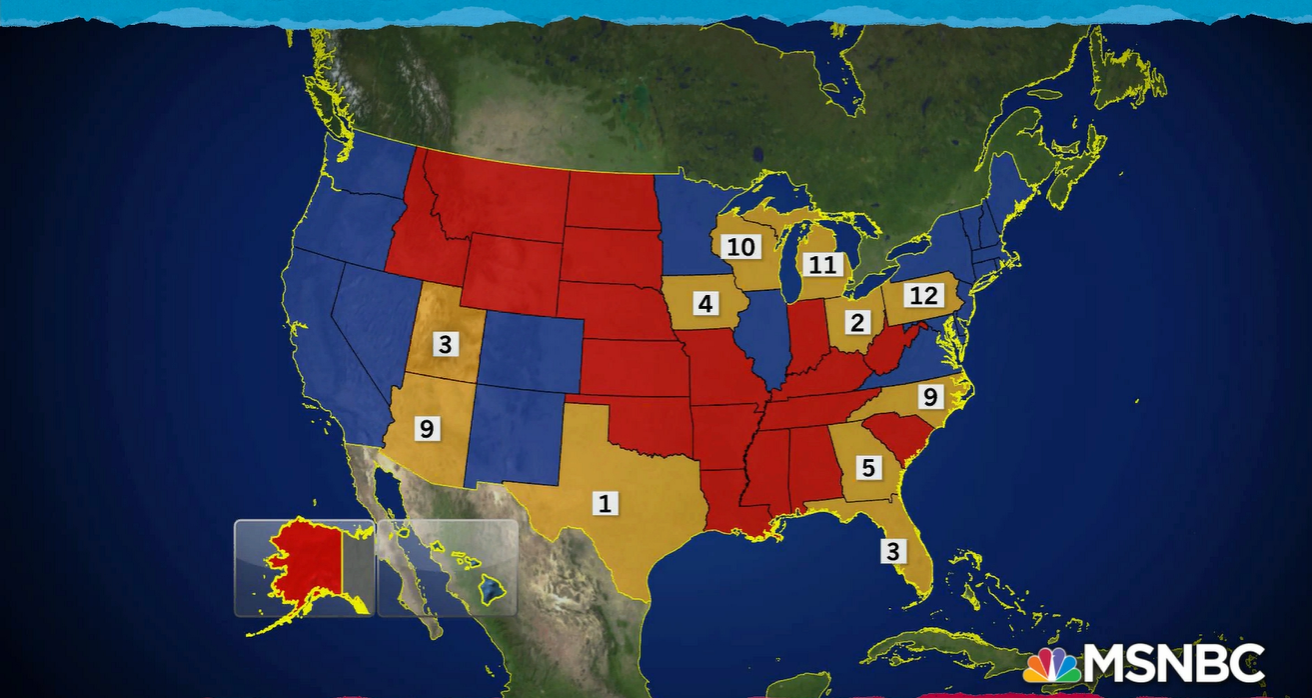 Looking at this map suggests that Trump may be in trouble since he is behind in the polls in many states that he won in 2016. Three of those states in particular Pennsylvania, Michigan and Wisconsin were crucial to his victory and his approval ratings are show more than 50% of the voters not approving of his performance. How this tanslates into votes in the upcoming election is yet to be seen. By the same token many things may happen between now and election time and they can have unpredictable effects on the outcome. Still, at this time it looks like Trump has a challenge on his hands.
The folks at Civiqs talk at length about their Research Panel from which their polling data is developed. The Research Panel is a large group of individuals who have agreed to participate in the many polls taken by Civiqs. The Research Panel technique while offering advantages, creates questions about the representativeness of the panel relative to those actually voting. That accuracy remains to be seen but it is likely that there is at a minimum some self-selection bias in the way the panel was developed. I have no doubt that sampling from the panel was done in the best way possible but the way the sample was created leaves the resulting sample in doubt. And, as we noted in that earlier missive poll accuracy is all about good sampling. Bottom line, if you are watching the polls to inform you of the direction the 2020 Presidential election is taking you can pretty much ignore the national poll results. You need to look at the state level returns to see which way each state is leaning and then add up their electoral votes. But, remember the polls have their own issues. Cornell Belcher made the same points on another MSNBC show but I can’t find the reference now. Last month (technically two months ago) I started talking about how much I enjoyed working with graduate students because I learned so much in the process. Of course, I got side tracked talking about regression. So, here, as Paul Harvey used to say, is the rest of the story. I learned about R the open source statistical package through working with a graduate student. I learned about Cohen’s d (the measure of the strength of relationship in analysis of variance) working with a graduate student. I never would have had the chance to employ dummy variables in using regression to do an analysis of variance (nice to know, stupid to do) and so much more. Since I am not active academically other than in helping graduate students and since I no longer belong to any professional associations for statisticians, one of my only ways of keeping current or even remembering my old learnings, is through helping others, be it in their graduate statistics classes or on their dissertations. A case in point is a student, whom I’ll call Kay. I tutored her in her nursing statistics class. She recently called and ask for help with a problem in statistical process control. I have not done anything in process control statistics since I started at Control Data Corporation in 1981! And even then, I had to learn it for the first time to present a model for applying process control to our yearly employee survey to our senior VPs. Deming (the godfather of process control statistics) was spinning in his grave at the thought. At any rate, helping Kay has given me the opportunity to brush up on my knowledge of process control statistics and I understand some of it really well now. There us of course still much to learn. One of the first students I worked with recently, I’ll call her Mandy, had been an employee of mine at one time. She had always given me a hard time about not finishing my doctorate and then she turned around and waited until the last minute to complete hers. By the time she was ready to work on her project her new major advisor had become the heard of the measurement department. He thought it would be fun for her to do her analysis of variance (ANOVA) in a regression framework using dummy coded variables. She panicked and called me. I panicked and read up on it! I had done plenty of regression analyses and ANOVAs and dummy coding, but never all at one time. The coding is simple, and the way it works out is simple for the main effects (main variables) but the interactions between variables are very tricky and we never used the interactions. That’s a very bad thing because it’s often the interactions that tell the story. A simple example of the importance of interactions is provided by the following example. Let’s say I have two groups of students, males and females. I want to test the effects of a certain teaching technique on their math performance. I test them pre and post and get the following two graphs. 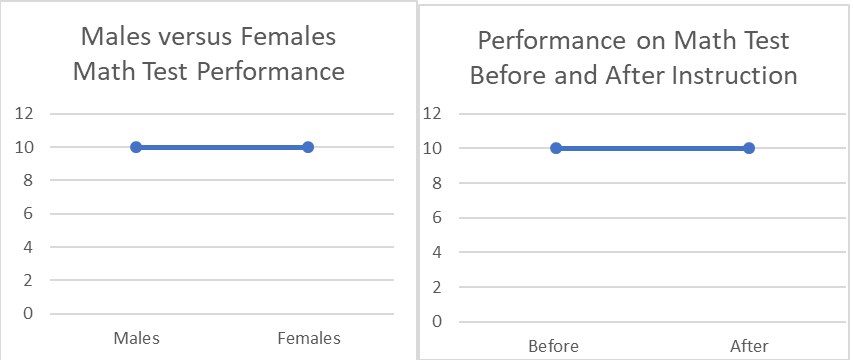 These figures depict the test scores on the main variables or the main effects of the experiment. Clearly, there are no differences between men and women on the test nor are there differences before and after instruction. However, if we look at the figure below clearly something very dramatic happened as a result of the instruction. Men and women changed places on the test! 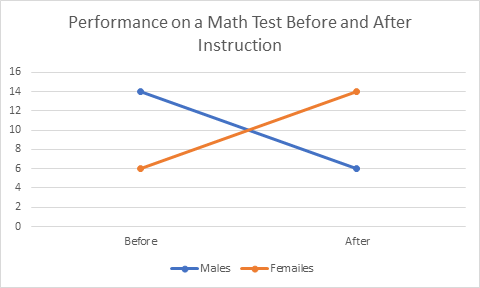 You will note that the mean score for men is ten both before and after instruction as it is for women so the first pictures are accurate but they mask the interaction effects. It is very important to always look at the interactions in a multi-variable experiment unless you know a priori that there will be no interaction effects. While it’s nice to see that regression can be used to perform an ANOVA for the purposes of showing the relationship between the two techniques it’s always a better idea to do an actual ANOVA if you are doing serious research.
|
AuthorEd Siegel Archives
May 2023
Categories |
 RSS Feed
RSS Feed
Site powered by Weebly. Managed by Hostgator